Trainiere dein eigenes Modell mit PhotonAI
Was ist PhotonAI ?
PhotonAI ist eine high-level Python API mit der schnell und einfach Machine Learning Pipelines erstellt werden können. Als Basis dienen bekannte Frameworks wie Scikit-learn und Keras. Durch die sogenannten Hyperpipes kann die Optimierung der Hyperparameter automatisiert werden und weitere Funktionen bietet die Möglichkeit verschiedene Verfahren zu vergleichen oder zu kombinieren. Der Wizard ermöglicht zudem die Generierung von PhotonAI Code über eine Weboberfläche und macht dadurch den Einstieg besonders einfach.
Für Python kann PhotonAI im Terminal direkt über pip installiert werden:
pip install photonai
Kompatibilitätsprobleme
Um diese zu vermeiden ist es ratsam, in einer virtuellen Umgebung zu arbeiten. Python bietet hierfür viele Möglichkeiten. Wir verwenden Virtualenv bzw. das seit Python 3.3 mitgelieferte Modul venv. Eine der bekanntesten Umgebungen ist Anaconda.
Projektordner und Daten
Klone oder Kopiere das Git Repository. Dann ist der Pfad zu diesem Projekt in dem Ordner zu finden wo das Repository liegt. Wir definieren den Pfad unten. Dieser muss angepasst werden.
In unserem Beispiel haben wir uns für einen frei verfügbaren Datensatz von Kaggle entschieden, welcher Daten und Preis zu gebrauchten Autos enthält (100,000 UK Used Car Data set). Lade diese Datei runter und gebe unten den Pfad zu den Daten an. Ebenfalls geben wir hier den Pfad an. Dieser muss angepasst werden.
PROJECT_DIR = "<pfad zum incubai repository>/1_1_PhotonAI/notebooks/"
DATA_DIR = "<pfad zu den daten>"Erstellung der Pipeline
Wir nutzen zur Erstellung unseres Modells zunächst den PhotonAI Wizard und entwerfen dort eine neue eigene Pipeline.
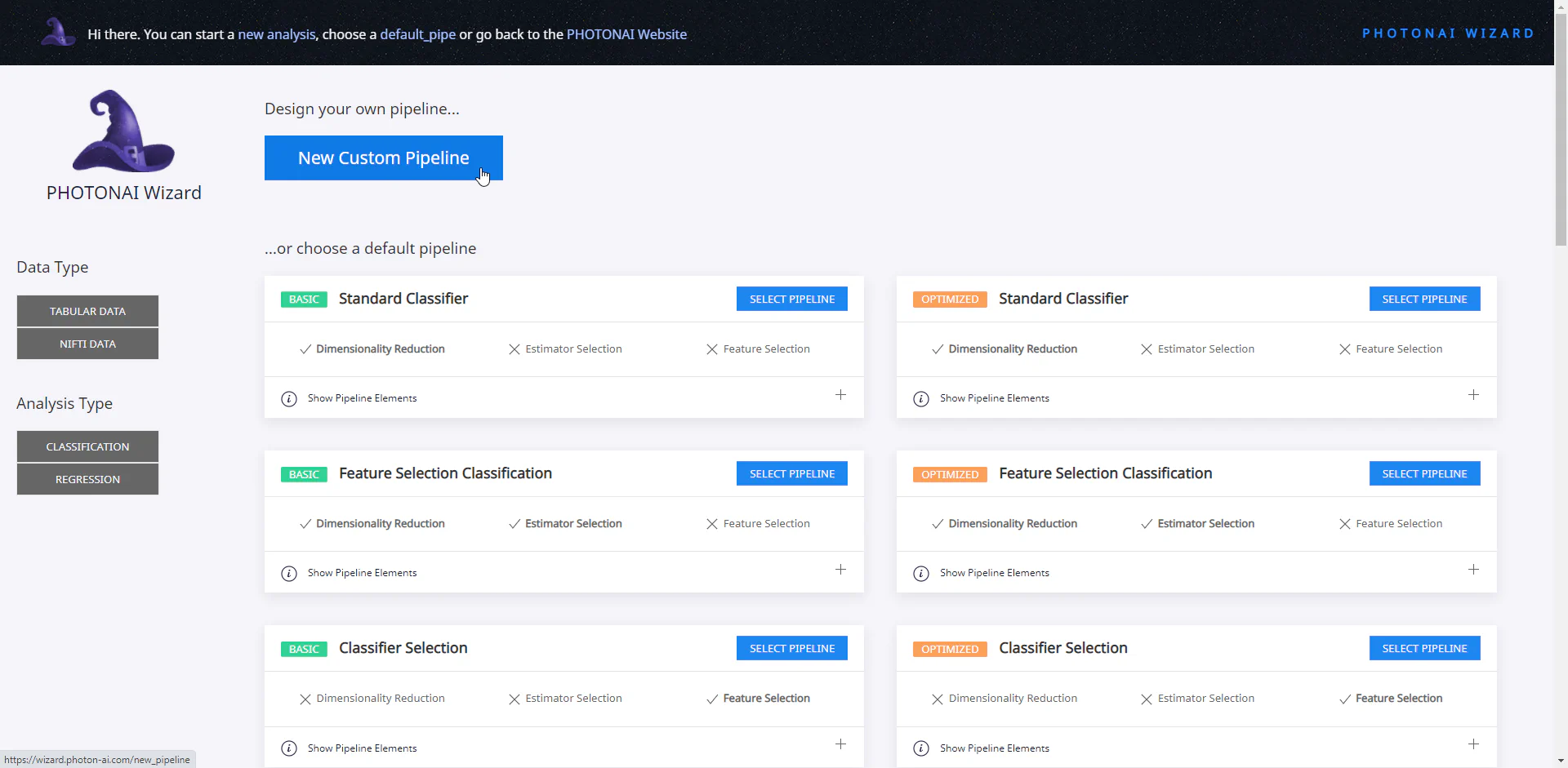
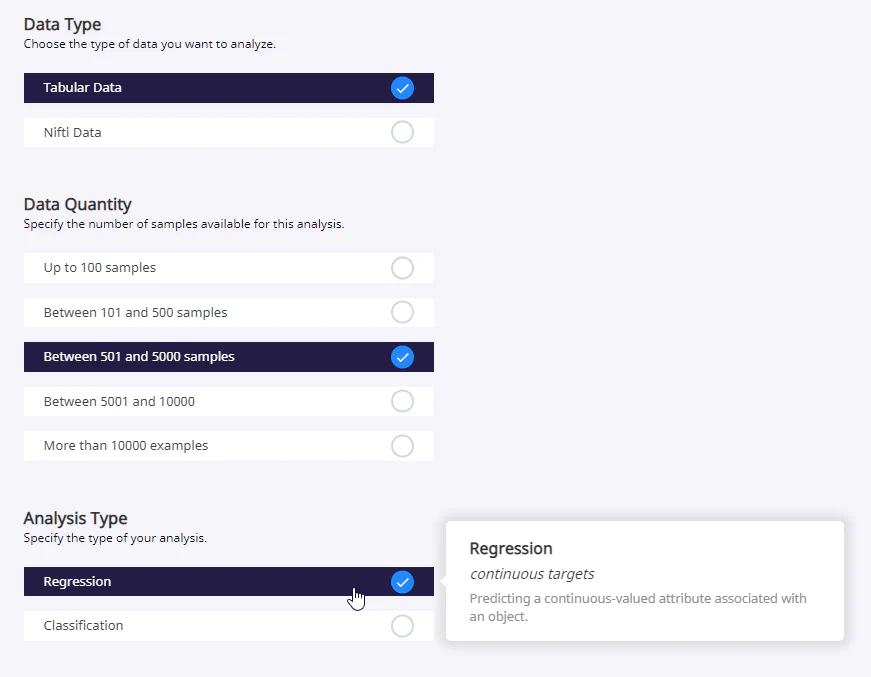
In unserem Beispiel haben wir uns für einen frei verfügbaren Datensatz von Kaggle entschieden, welcher Daten und Preis zu gebrauchten Autos enthält (100,000 UK Used Car Data set). Wir werden uns auf einen Autohersteller (VW) beschränken und versuchen den Preis vorherzusagen. Die ersten Einstellungen sind direkt abhängig vom Aufbau unseres Datensatzes und unserer Aufgabe. Sie können sich deshalb bei anderen Daten unterscheiden. Die vereinfachte Bedienung von PhotonAI und insbesondere dem Wizard führt allerdings dazu, dass einige Daten und Aufgaben (noch) nicht unterstützt werden. So stehen im Wizard bisher nur tabellarische und Nifti Daten zur Auswahl. Außerdem gibt es nur die Möglichkeit eine Regression oder Klassifikation durchzuführen. Für andere Daten- oder Analysetypen muss deshalb doch auf TensorFlow, PyTorch oder ähnliche Packages zurückgegriffen werden.
 Während man die verschiedenen Einstellungen vornimmt, kann man live auf der rechten Seite den entsprechenden Programmcode betrachten. Dadurch eignet sich der Wizard auch, um die Benutzung des PhotonAI Packages zu lernen. Wir fügen in unserem Beispiel zwei unterschiedliche Estimator hinzu, deren Performance von PhotonAI später automatisch verglichen wird.
Während man die verschiedenen Einstellungen vornimmt, kann man live auf der rechten Seite den entsprechenden Programmcode betrachten. Dadurch eignet sich der Wizard auch, um die Benutzung des PhotonAI Packages zu lernen. Wir fügen in unserem Beispiel zwei unterschiedliche Estimator hinzu, deren Performance von PhotonAI später automatisch verglichen wird.
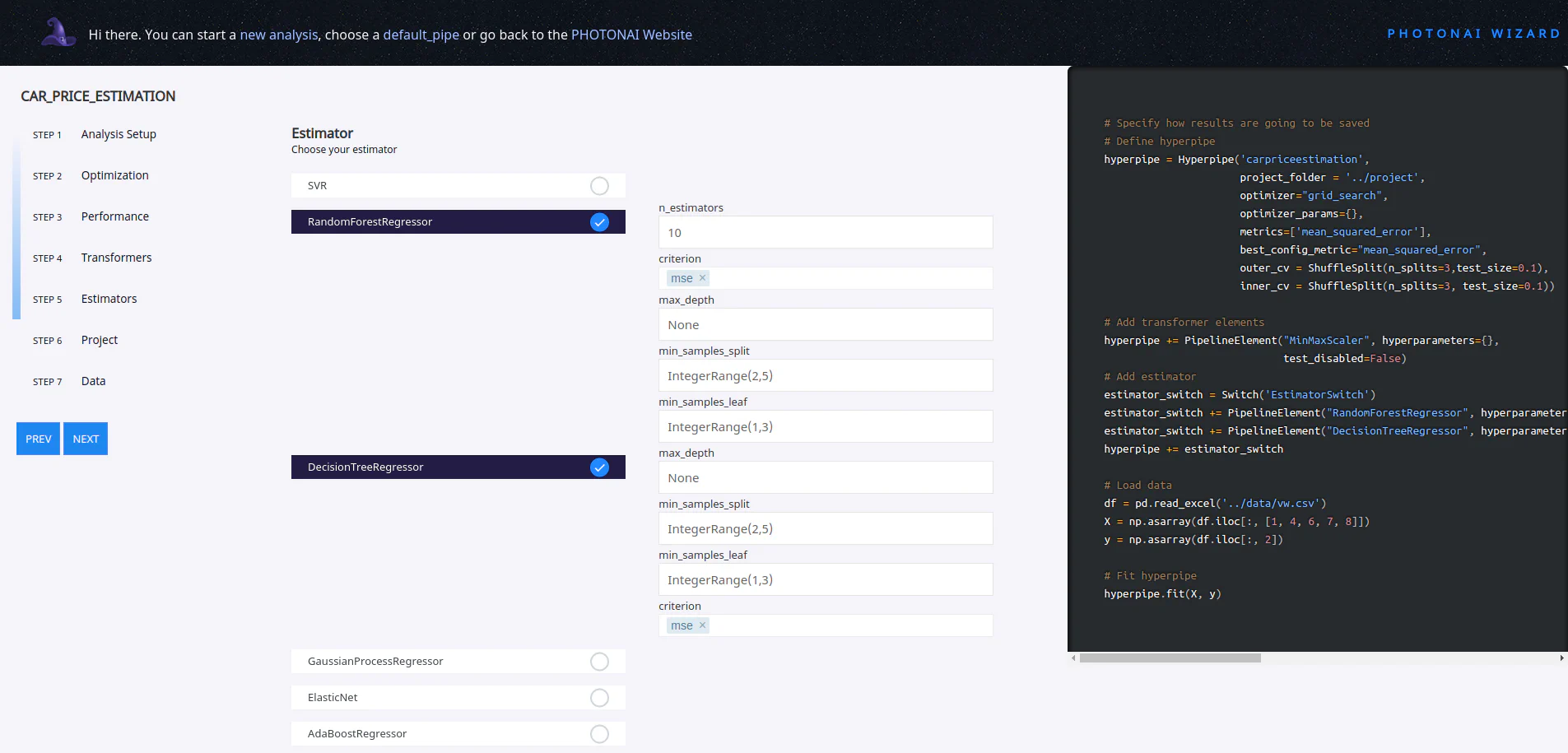
Der erstellte Code kann jetzt heruntergeladen werden. Hierbei ist wie im folgenden Code drauf zu achten, dass die Struktur eingehalten wird. Dieses Jupyter-Notebook liegt beispielsweise in dem Ordner app, welcher sich zusammen zudem mit dem Ordner project auf der gleichen Datenebene (1_1_PhotonAI) befindet. Der Ordner project dient dabei PhotonAI als Zwischenspeicher für Logs und Modelle.
Anpassung der Pipline
Der durch den Wizard bereitgestellte Code geht von einer Exel-Tabelle als Datensatz aus. Deshalb muss in dem Code in dem Abschnitt: Load data das read_exel() durch read_csv ersetzt werden.
Pass bitte auch den Pfad zu den Daten an!
Training des Modells
DIe Pipline solle jetzt bereit sein. Die folgende Zelle kann ausgeführt werden. Während des Trainings erhalten wir auf der Konsole regelmäßige Updates über die Performance und am Ende eine kurze Zusammenfassung über die besten Konfigurationen, die die Hyperparameter-Suche ergeben hat.
# Beispielkonfiguration
# -------------------- GENERATED WITH PHOTON WIZARD (beta) ------------------------------
# PHOTON Project Folder: ../project
import pandas as pd
import numpy as np
from photonai.base import Hyperpipe, PipelineElement, Switch
from photonai.optimization import IntegerRange
from sklearn.model_selection import ShuffleSplit
# Specify how results are going to be saved
# Define hyperpipe
hyperpipe = Hyperpipe('carpriceestimation',
project_folder='../project',
optimizer="grid_search",
optimizer_params={},
metrics=['mean_squared_error'],
best_config_metric="mean_squared_error",
outer_cv=ShuffleSplit(n_splits=3, test_size=0.1),
inner_cv=ShuffleSplit(n_splits=3, test_size=0.1))
# Add transformer elements
hyperpipe += PipelineElement("MinMaxScaler", hyperparameters={},
test_disabled=False)
# Add estimator
estimator_switch = Switch('EstimatorSwitch')
estimator_switch += PipelineElement("RandomForestRegressor",
hyperparameters={
'min_samples_split': IntegerRange(2, 5),
'min_samples_leaf': IntegerRange(1, 3)
},
n_estimators=10,
criterion='squared_error',
max_depth=None)
estimator_switch += PipelineElement("DecisionTreeRegressor",
hyperparameters={
'min_samples_split': IntegerRange(2, 5),
'min_samples_leaf': IntegerRange(1, 3)
},
max_depth=None,
criterion='squared_error')
hyperpipe += estimator_switch
# Load data
# PLEASE UPDATE DATA DIR HERE!
df = pd.read_csv(f'{DATA_DIR}/vw.csv')
X = np.asarray(df.iloc[:, [1, 4, 6, 7, 8]])
y = np.asarray(df.iloc[:, 2])
# Fit hyperpipe
hyperpipe.fit(X, y)Zusätzlich wird in +project/+ ein neuer Ordner angelegt, der einige Dateien mit wichtigen Informationen zu dem Trainingsdurchlauf enthält. Besonders wichtig sind hier natürlich das optimale Modell photon_best_model.photon und die die Datei photon_result_file.json. Diese kann mit dem PhotonAI Explorer betrachtet werden. Zunächst wird eine Zusammenfassung der kompletten Pipeline angezeigt. In unserem Falls können wir hier direkt sehen, dass der RandomForestRegressor besser abgeschnitten hat als der DecisionTreeRegressor.

Neben zahlreichen anderen Plots können wir beispielsweise mit dem direkten Vergleich von vorhergesagten Preisen und Ground Truth Preisen die Performance unseres Modells evaluieren.

Modell testen
Zwar sind die im Explorer angezeigten Plots und Metriken äußerst hilfreich bei der Evaluation unseres Modells, dennoch wollen wir unser fertiges Modell auch mit eigenen Eingaben nochmal testen. Daztu nutzen wir den unten stehenden Code.
Der Dateipfad muss noch bei best_model_path eingefügt werden. Dieser kann ggf. in dem Ordner project/carpriceestimation_result nachvollzogen werden.
from photonai.base import Hyperpipe
dummy_data = [[2019, 12132, 145, 42.7, 2.0]]
RESULT_DIR = "<path to result>"
# e.g. carpriceestimation_results_2023-11-15_12-03-05
best_model_path = f'{PROJECT_DIR}/{RESULT_DIR}/best_model.photonai'
hyperpipe = Hyperpipe.load_optimum_pipe(file=best_model_path)
result = hyperpipe.predict(dummy_data)
result = hyperpipe.inverse_transform(result.reshape([1, -1]))[0][0, 0]
print(result)